We use PostgreSQL at work, but like many developers working behind modern frameworks and ORMs, I’ve mostly interacted with the database through abstractions, setting up models, defining tables, and writing fairly simple queries. I’ve rarely looked under the hood at how Postgres actually executes those queries.
PostgreSQL has recently been making a splash on the internet with the OpenAI engineering post about how they optimize queries. Reading through that made me realize that query planning is still a complete black box to me.
This series is my attempt to change that, to understand what Postgres is really doing when we hit “run,” and hopefully make databases feel a little less mysterious for anyone else in the same boat.
When you type a simple query like -
Modern SQL Editors return the results in milliseconds, regardless of table size. This seemingly instantaneous result is powered by Relational Algebra which is the foundation of SQL and modern databases.
Algebraic Notations & Expression Trees
While relational algebra gives us the language to describe what a query is doing, databases internally need a structure that is easier to optimize, and execute. This is where expression trees come in.
An expression tree is essentially a tree representation of a query where:
- Each node represents an operation (selection σ, projection π, join ⨝, etc.)
- The leaves represent base tables
- The root represents the final result returned to the user
This follows the sequence of operations Postgres takes under the hood executing each query as a series of algebraic operations stacked on top of each other.
Query 1 using Projection to select columns -
Query 2 using Selection to filter rows via condition -
Expression Tree -
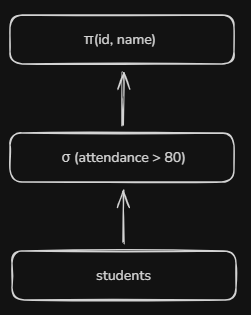
Conceptually, this says:
- Start with the Students table
- Filter rows where attendance > 80
- Return only the id and name column
Query 3 using Join to join columns from two or more tables:
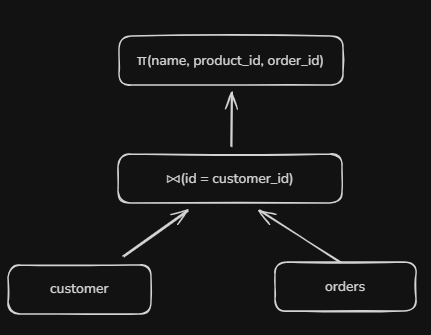
Databases Don’t Always Execute Trees Top-Down
One of the first surprising things about query planning is that the logical order of operations is not necessarily the physical order of execution.
The tree above is a logical representation — a clean mathematical description of the query. But Postgres’ query planner is free to rearrange parts of this tree if it can produce the same result more efficiently.
This is where optimization begins.
Core Optimization Rules
Rule: Reordering Selection and Projection
The optimizer can reorder selection and projection operations to minimize data processing. Consider our previous query modified to select specific columns:
With a table `Students` having over 50+ columns, if we can somehow only keep the columns we need before we even perform the filtering, we will remove all unused columns lowering memory usage.
An alternative expression tree may look like -
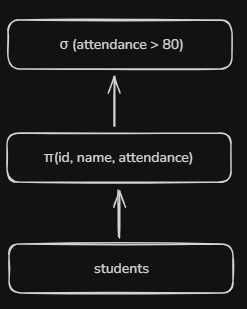
The optimizer might reorder these operations, ensuring necessary columns are retained while minimizing data movement. This becomes particularly important when working with large tables where reducing the data set early can significantly improve performance.
Rule: Join Optimization
An alternative expression tree may look like -
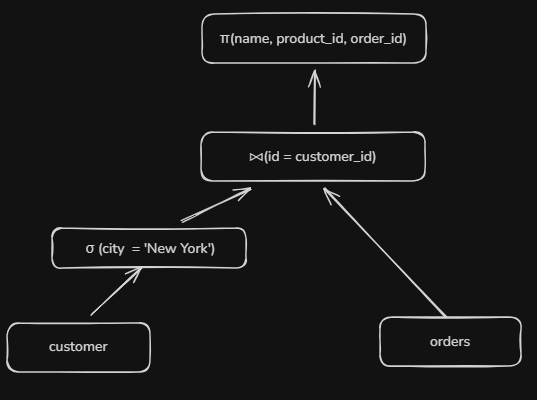
This transformation reduces the number of rows involved in the join operation which again, contributes to performance improvement since we are carrying less unused data around.
Ultimately Postgres uses statistics about column value distributions to estimate result set size and choose appropriate execution strategies. What ends up driving the decision behind which path to take is the actual table sizes, the column correlation, and distribution of data. Some optimizations always make sense like projecting/filtering early but simple rules are not enough – Postgres uses this as a base for correction.
In reality, Postgres goes through multiple internal representations:
- SQL → parsed into a syntax tree
- Converted into relational algebra–like structures
- Transformed into optimised expression trees
- Finally turned into a physical execution plan involving:
- Sequential scans
- Index scans
- Hash joins
- Nested loops
The expression tree is the stage where Postgres begins to ask:
“Are there equivalent ways to produce the same result with less work?”
And that question is at the heart of query planning.
When we rely heavily on ORMs and abstractions, it’s easy to think of SQL as declarative magic — write a query, get results. But under the hood, Postgres is actively restructuring our queries into trees, transforming operations, and estimating costs.
Understanding expression trees helps explain why:
- The same query can run faster after adding an index
- Small changes in column selection can improve performance
- The execution plan sometimes looks nothing like the SQL we wrote
In the next section, we’ll move one step closer to reality, looking at how Postgres turns these logical trees into actual execution plans and how tools like EXPLAIN/ANALYZE let us peek inside the black box.